Welcome to quanda’s documentation!¶
quanda is a toolkit for quantitative evaluation of data attribution methods in PyTorch.
Note
quanda is under active development. Note the release version to ensure reproducibility of your work. Contributions, bug reports, and feature requests are welcome.

Fig. 1: quanda provides a unified and standardized framework to evaluate the quality of Training Data Attribution methods in different contexts and from different perspectives.¶
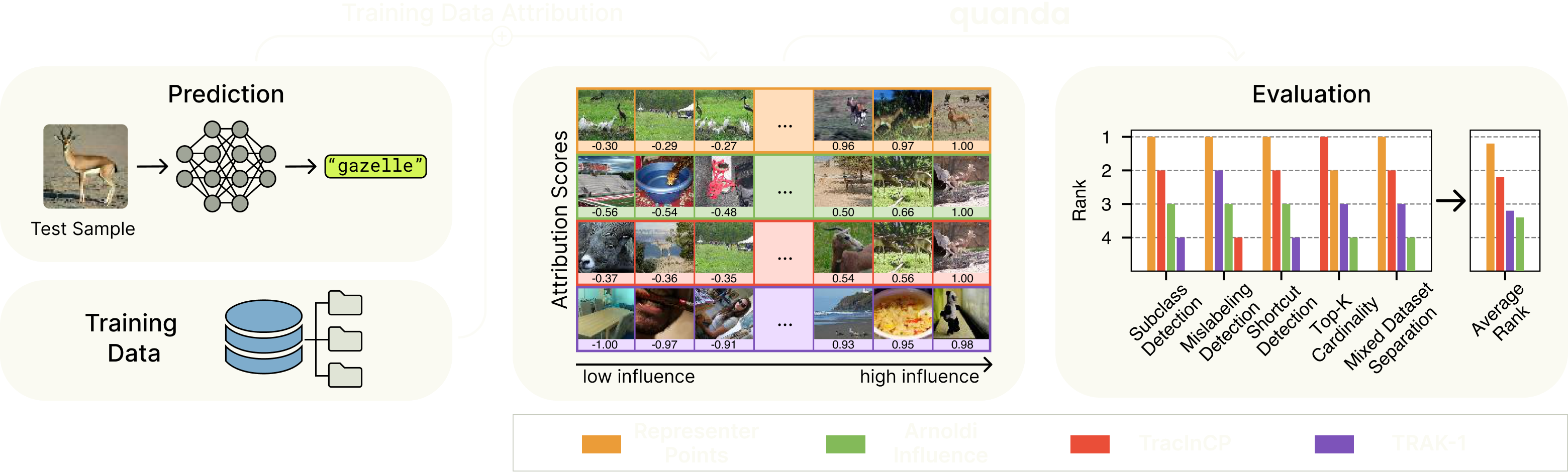
Fig. 1: quanda provides a unified and standardized framework to evaluate the quality of Training Data Attribution methods in different contexts and from different perspectives.¶
Note
This page describes quanda’s purpose, design and features. For a quick start on quanda, please refer to the Quickstart page.
Training Data Attribution (TDA) is a new avenue in the interpretation of neural networks. While some methods attempt to estimate the counterfactual effects of training new models on the subsets of the training dataset, this ground truth is noisy and hard to compute. Therefore, the community has proposed evaluating these methods’ performance on a downstream task, or measuring how well a method satisfies desired heuristic properties.
quanda is designed to meet the need of a comprehensive and systematic evaluation framework, as well as a unified interface for attributors. Please visit the Background page for a detailed explanation of TDA, including citations to the relevant literature.
Library Features¶
Here we list the main components of quanda along with basic explanations of their function. We refer the reader to the Contribution guide, the API reference and the Basic Usage for further details. Below is a schematic representation of the components of quanda:

Fig. 2: Components and their interactions in quanda¶

Fig. 2: Components and their interactions in quanda¶
Explainers
quanda provides a unified interface for various TDA methods, symbolized by the Explainer base class. The interface design prioritizes ease of use and easy extensions, allowing users to quickly wrap their implementations to use within quanda.
Metrics
quanda provides a set of metrics to evaluate the effectiveness of TDA methods. These metrics are based on the latest research in the field. Most Metric objects in quanda are used to compute the evaluation scores from attributions over a test set. The Metric objects are designed to be easily extendable, allowing users to define their own metrics.
Benchmarks
Note that many metrics require training models in controlled settings, e.g. with mislabeled samples that are known. This means that the corresponding Metric objects can only be used if the user has prepared this controlled setup. Furthermore, Metric objects require generating the attributions beforehand. quanda provides a benchmarking tool to evaluate the performance of TDA methods on a given model, dataset and problem. For each Metric object, quanda provides a Benchmark object. The Benchmark objects handle the creation of the controlled setup, training the model, generating the attributions and evaluating them using the corresponding Metric object, if needed. Finally, we provide precomputed benchmarks, which can be used by initializing the object with the load_pretrained method. These precomputed benchmarks allow the user to skip the creation of the controlled setup to directly start the evaluation process, while providing a standard benchmark for practitioners and researchers to compare their methods with.
Supported TDA Libraries¶
Library |
Reference |
|---|---|
Captum (Similarity Influence, Arnoldi Influence Functions, TracIn) |
Caruana et al., 1999; Schioppa et al., 2022; Koh and Liang, 2017; Pruthi et al., 2020 |
Representer Point Selection (Representer Point Selection) |
|
TRAK (TRAK) |
|
Kronfluence (Kronfluence) |
|
Dattri (Influence Functions: Explicit / CG / LiSSA / DataInf, Arnoldi, EK-FAC, TracInCP, Grad-Dot, Grad-Cos, TRAK) |
Evaluation Metrics¶
In this section, we list the evaluation criteria that are currently available in quanda.
Name |
Reference |
Description |
Type |
|---|---|---|---|
Linear Datamodeling Score |
Measures the correlation between the (grouped) attribution scores and the actual output of models trained on different subsets of the training set. For each subset, the linear datamodeling score compares the actual model output with the sum of attribution scores from the subset using Spearman rank correlation. |
Ground Truth |
|
Class Detection / Subclass Detection |
Measures the proportion of identical classes or subclasses in the top-1 training samples over the test dataset. If the attributions are based on similarity, they are expected to be predictive of the class of the test datapoint, as well as different subclasses under a single label. |
Downstream Task Evaluator |
|
Shortcut Detection |
Assuming a known shortcut, or Clever-Hans effect has been identified in the model, this metric evaluates how effectively a TDA method can identify shortcut samples as the most influential in predicting cases with the shortcut artifact. This process is referred to as Domain Mismatch Debugging in the original paper. |
Downstream Task Evaluator |
|
Mislabeled Data Detection |
Computes the proportion of noisy training labels detected as a function of the percentage of inspected training samples. The samples are inspected in order according to their global TDA ranking, which is computed using local attributions. This produces a cumulative mislabeling detection curve. We expect to see a curve that rapidly increases as we check more of the training data, thus we compute the area under this curve. |
Downstream Task Evaluator |
|
Top-K Cardinality |
Measures the cardinality of the union of the top-K training samples. Since the attributions are expected to be dependent on the test input, they are expected to vary heavily for different test points, resulting in a low overlap (high metric value). |
Heuristic |
|
Model Randomization |
Measures the correlation between the original TDA and the TDA of a model with randomized weights. Since the attributions are expected to depend on model parameters, the correlation between original and randomized attributions should be low. |
Heuristic |
|
Mixed Datasets |
In a setting where a model has been trained on two datasets: a clean dataset (e.g. CIFAR-10) and an adversarial (e.g. zeros from MNIST), this metric evaluates how well the model ranks the importance (attribution) of adversarial samples compared to clean samples when making predictions on an adversarial example. |
Heuristic |
|
Mean Reciprocal Rank (MRR) |
For fact-tracing settings, measures the mean reciprocal rank of the highest-ranked entailing proponent across fact queries. |
Downstream Task Evaluator |
|
Recall@k |
For fact-tracing settings, measures the proportion of facts for which an entailing proponent appears in the top-k retrievals. |
Downstream Task Evaluator |
|
Tail Patch |
For fact-tracing settings, measures the incremental change in target-sequence probability after taking a single training step on retrieved proponents. |
Downstream Task Evaluator |
Metric Interpretation Guideline¶
Metric |
Output range |
Better |
|---|---|---|
|
higher |
|
|
higher |
|
|
higher |
|
|
higher |
|
|
higher |
|
|
higher |
|
|
closer to 0 |
|
|
higher |
|
|
higher |
|
|
higher |
|
|
higher |
Benchmarks¶
quanda comes with a number of pre-computed benchmarks that can be conveniently used for evaluation in a plug-and-play manner. We are planning to significantly expand the number of benchmarks in the future. Currently available benchmarks span vision (MNIST / LeNet, CIFAR-10 / ResNet-9, AWA2 / ResNet-50), text classification (QNLI / BERT), and causal language modeling (T-REx / GPT-2 fine-tuned on OpenWebText). The benchmark IDs listed below are to be passed to load_pretrained.
Metric |
Type |
Modality |
Benchmark IDs (Dataset / Model) |
|---|---|---|---|
Heuristic |
Vision |
mnist_top_k_cardinality (MNIST / LeNet)
cifar_top_k_cardinality (CIFAR-10 / ResNet-9)
awa2_top_k_cardinality (AWA2 / ResNet-50)
|
|
Text |
qnli_top_k_cardinality (QNLI / BERT) |
||
Heuristic |
Vision |
mnist_model_randomization (MNIST / LeNet)
cifar_model_randomization (CIFAR-10 / ResNet-9)
awa2_model_randomization (AWA2 / ResNet-50)
|
|
Text |
qnli_model_randomization (QNLI / BERT) |
||
Heuristic |
Vision |
mnist_mixed_datasets (MNIST / LeNet)
cifar_mixed_datasets (CIFAR-10 / ResNet-9)
awa2_mixed_datasets (AWA2 / ResNet-50)
|
|
Text |
qnli_mixed_datasets (QNLI / BERT) |
||
Downstream Task Evaluator |
Vision |
mnist_class_detection (MNIST / LeNet)
cifar_class_detection (CIFAR-10 / ResNet-9)
awa2_class_detection (AWA2 / ResNet-50)
|
|
Text |
qnli_class_detection (QNLI / BERT) |
||
Downstream Task Evaluator |
Vision |
mnist_subclass_detection (MNIST / LeNet)
cifar_subclass_detection (CIFAR-10 / ResNet-9)
awa2_subclass_detection (AWA2 / ResNet-50)
|
|
Downstream Task Evaluator |
Vision |
mnist_mislabeling_detection (MNIST / LeNet)
cifar_mislabeling_detection (CIFAR-10 / ResNet-9)
awa2_mislabeling_detection (AWA2 / ResNet-50)
|
|
Text |
qnli_mislabeling_detection (QNLI / BERT) |
||
Downstream Task Evaluator |
Vision |
mnist_shortcut_detection (MNIST / LeNet)
cifar_shortcut_detection (CIFAR-10 / ResNet-9)
awa2_shortcut_detection (AWA2 / ResNet-50)
|
|
Downstream Task Evaluator |
Causal LM |
gpt2_trex_openwebtext_ft_mrr (T-REx / GPT-2 fine-tuned on OpenWebText) |
|
Downstream Task Evaluator |
Causal LM |
gpt2_trex_openwebtext_ft_recall_at_k (T-REx / GPT-2 fine-tuned on OpenWebText) |
|
Downstream Task Evaluator |
Causal LM |
gpt2_trex_openwebtext_ft_tail_patch (T-REx / GPT-2 fine-tuned on OpenWebText) |
|
Ground Truth |
Vision |
mnist_linear_datamodeling (MNIST / LeNet)
cifar_linear_datamodeling (CIFAR-10 / ResNet-9)
awa2_linear_datamodeling (AWA2 / ResNet-50)
|
|
Text |
qnli_linear_datamodeling (QNLI / BERT) |
Citation¶
If you find quanda useful and want to use it in your research, please cite it using the following BibTeX entry:
@misc{bareeva2024quandainterpretabilitytoolkittraining,
title={Quanda: An Interpretability Toolkit for Training Data Attribution Evaluation and Beyond},
author={Dilyara Bareeva and Galip Ümit Yolcu and Anna Hedström and Niklas Schmolenski and Thomas Wiegand and Wojciech Samek and Sebastian Lapuschkin},
year={2024},
eprint={2410.07158},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2410.07158},
}
If you are using quanda for your scientific research, please also make sure to cite the original authors for the implemented metrics and TDA methods.
Usage
API Reference
Community